Discover AI Research
Explore the latest papers, methods, and breakthroughs
from the world's AI research community.
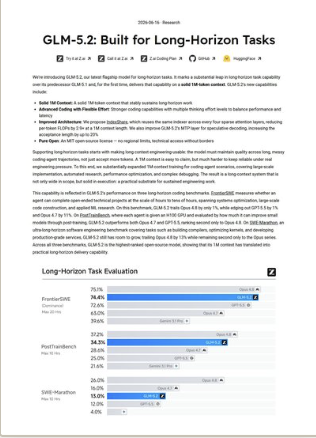
GLM-5.2: Built for Long-Horizon Tasks
Z.ai Team · Jun 16, 2026
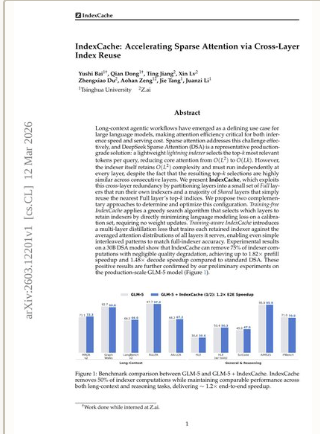
IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
Yushi Bai, Qian Dong, Ting Jiang, +5 authors · Mar 12, 2026

Darwin Family: MRI-Trust-Weighted Evolutionary Merging for Training-Free Scaling of Language-Model Reasoning
Taebong Kim, Youngsik Hong, Minsik Kim, +4 authors · May 14, 2026

Qwen3.5: Towards Native Multimodal Agents
Qwen Team · Feb 16, 2026
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, +26 authors · Jan 6, 2026
NVIDIA Nemotron 3: Efficient and Open Intelligence
Nvidia, Aaron Blakeman, Aaron Grattafiori, +355 authors · Dec 24, 2025
DFlash: Block Diffusion for Flash Speculative Decoding
Jian Chen, Yesheng Liang, Zhijian Liu · Feb 5, 2026
Tmax: A simple recipe for terminal agents
Hamish Ivison, Junjie Oscar Yin, Rulin Shao, +3 authors · Jun 22, 2026
Qwen3.6
Qwen · Apr 21, 2026
VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
Sen Xu, Shixi Liu, Wei Wang, +6 authors · Jun 15, 2026
Qwen3-TTS Technical Report
Hangrui Hu, Xinfa Zhu, Ting He, +13 authors · Jan 22, 2026
QUEST: Training Frontier Deep Research Agents with Fully Synthetic Tasks
Jian Xie, Tianhe Lin, Zilu Wang, +16 authors · May 22, 2026
Data Science and Technology Towards AGI Part I: Tiered Data Management
Yudong Wang, Zixuan Fu, Hengyu Zhao, +14 authors · Feb 9, 2026
MiniMax Sparse Attention
Xunhao Lai, Weiqi Xu, Yufeng Yang, +8 authors · Jun 11, 2026
MOSS-TTS Technical Report
Yitian Gong, Botian Jiang, Yiwei Zhao, +23 authors · Mar 18, 2026
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
DeepSeek-AI · Apr 24, 2026
Holo3.1: Fast & Local Computer Use Agents
Holo Team · Jun 1, 2026
FastContext: Training Efficient Repository Explorer for Coding Agents
Shaoqiu Zhang, Maoquan Wang, Yuling Shi, +5 authors · Jun 12, 2026
Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs
Dekoninck, Jasper, Jovanović, Nikola, Gehrunger, Tim, +4 authors · May 1, 2026
ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation
Junmin Gong, Yulin Song, Wenxiao Zhao, +3 authors · Jan 31, 2026
Mix, MinHash, and Match: Cross-Source Agreement for Multilingual Pretraining Datasets
Sultan Alrashed, Francesco Orabona · Dec 21, 2025
HRM-Text: Efficient Pretraining Beyond Scaling
Guan Wang, Changling Liu, Chenyu Wang, +6 authors · May 20, 2026
MolmoMotion: Forecasting Point Trajectories in 3D with Language Instruction
Jianing Zhang, Chenhao Zheng, Yajun Yang, +10 authors · Jun 17, 2026
Rethinking Generalization in Reasoning SFT: A Conditional Analysis on Optimization, Data, and Model Capability
Qihan Ren, Peng Wang, Ruikun Cai, +8 authors · Apr 8, 2026
Introducing Gemma 4 12B: a unified, encoder-free multimodal model
Google DeepMind · Jun 3, 2026
Stable Audio 3
Zach Evans, Julian D. Parker, Matthew Rice, +4 authors · May 18, 2026
LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
Shihao Wang, Shilong Liu, Yuanguo Kuang, +10 authors · May 26, 2026